Siber güvenliğin koruması gereken yeni alan: Yapay zekâ

08/12/2022 11:05
08/12/2022 11:05
Yapay zekâ konusu, kökeni çok eskilere dayanıyor olsa da en büyük ilerlemesini son 10 yılda gerçekleştirmiştir. Artık sadece araştırma merkezleri ve üniversitelerde kullanılır olmaktan çıkıp lojistik, sağlık, otonom araçlar gibi birçok ticari alanda da kullanılmaya başlanmıştır. Günümüzde bu kadar yaygınlaşmasının başlıca nedenlerinden bir tanesi, günümüz bilgisayarlarının hesaplama gücünün, bu algoritmaların tasarlandığı zamana göre çok ilerlemiş olmasıdır. Sahip olduğumuz yüksek kapasiteli bilgisayarlar ve depolama üniteleri sayesinde, algoritmaların ihtiyaç duyduğu yüksek miktarda veriyi kayıt altına alarak sadece bilgisayarların merkezi işlemcilerinde değil, aynı zamanda grafik kartlarının sahip olduğu grafik işleme birimleri (Graphical Processing Unit – GPU) kullanılarak eğitim aşaması gerçekleştirilmekte ve günler veya haftalar sürecek bu faz, saatler veya dakikalar seviyesine düşürülebilmektedir.
Arkalarındaki matematiksel temeller birkaç on yıl önce geliştirilmiş olsa bile, güçlü GPU’ların nispeten yeni ortaya çıkışıyla beraber, bu alanda yer alan araştırmacılar, karmaşık makine öğrenme sistemlerini denemek ve oluşturmak için gerekli hesaplama gücünü yeni elde etmişlerdir. Bugün, bilgisayarla görü için kullanılan VGG19, ResNet, DenseNet ve Inception gibi son teknoloji modelleri, birkaç milyon parametre içeren derin sinir ağlarından oluşmaktadır ve sadece on yıldır mevcut olan bir donanıma dayanmaktadır.
Yapay zekâ alanında gerçekleşen bu göz kamaştırıcı ilerlemeye rağmen, diğer yeni teknolojilerin göz ardı ettiği ve ilerleyen zamanlarda büyük problemler yaşadığı güvenlik konusu, yine ihmal edilmektedir. TCP/IP protokolü, ilk tasarlandığı zaman, ölçek olarak oldukça az sayıda bilgisayarın bağlı olduğu bir ağ üzerinde olması nedeniyle güvenlik konusu düşünülmeden geliştirilmiştir. İnternet’in ölçek ve karmaşıklığının hızla artmasıyla beraber, tasarımcıların öngöremediği bu protokol eksikliklerinden faydalanan saldırganlar, günümüzde etkilerini hala sürdürebilmektedir.
Benzer bir durum yapay zekâ için de geçerlidir. Makine öğrenme algoritmalarının hemen hemen tamamı, çeşitli güvenlik zafiyetleri içermektedir. Genellikle bu saldırıların tümü algoritmanın eğitim veya sınıflandırma aşamalarında saldırgan girdi örneklerini (adversarial instances) kullanarak modelin manipülasyonunu hedeflemektedir.
Saldırgan girdi örnekleri, makine öğrenme modellerini kandırmak için tasarlanmış kötü niyetli girdilerdir. Bir saldırganın bakış açısıyla, yanlış sınıflandırılmış bir örnekle bir tespit sistemini atlatmaya ya da makine öğrenmesi modelini eğitim aşamasında tutarlı bir şekilde yanlış sınıflandıracak şekilde öğrenmeye zorlayabilirler.
Örnek Saldırı
Günlük yaşantımızdan bu duruma verilebilecek en iyi örnek siber güvenlik bileşenleridir. Kurumsal ağlar üzerinde makine öğrenme modellerine dayalı olarak çalışacak IPS/IDS sistemlerinin, kurulum yapıldıkları yaklaşık 3 ay süresince ağ üzerinde veri toplama ve öğrenme sürecine devam edeceği, ilgili ticari üreticiler tarafından belirtilmektedir. Bu 3 aylık eğitim süresince ağ içerisinde yer alan bir saldırgan veya saldırganın geliştirdiği bir zararlı yazılım, pozitif örnek olarak işaretlenecek olan anomali hareketleri, ağ paketleri üzerinde yapacağı etiket değişikleri ile yaptığı işlemlerin zararsız olarak işaretleyebilir. Bu durumda, 3 ay sonunda kullanılacak olan zararlı ağ tespit modeli, hatalı veriyle eğitilmiş olacağı için hatalı sınıflandırma işlemi yapacaktır. Bu tip saldırılara etiket değişikliği saldırısı (label flipping attack) adı verilmektedir ve eğitim aşamasında geçmektedir.
Ek olarak saldırgan, girdi örneklerinde manipülasyonlar yaparak modeli atlatabilir. Buna verilebilecek örneklerden bir tanesi, ikili sınıflandırma yöntemlerinden olan lojistik regresyon yönteminin atlatılmasıdır. Lojistik regresyon çok kısa olarak anlatılacak olursa, doğrusal bir denklem kullanarak sonucun 0.5’ten büyük olması durumunda örneği pozitif, 0.5’ten az olması durumunda negatif olarak işaretlemektedir (saldırı örneği olarak ifade edilirse; pozitif sonuç saldırı var, negatif sonuç ise normal davranış şeklindedir).
Örnek olarak, sahip olduğumuz ağ saldırısını tespit edebilen lojistik regresyon sınıflandırma modelinin ağırlıkları (w) ve sınıflandırma yapılacak olan girdi örneği (ağ paketi x) Tablo 1’de gösterilmektedir. Son satırda ağırlık sonucu -3 çıkmaktadır. Lojistik regresyon denkleminde yerine koyulmasıyla elde edilen sonuç 0.0474, yani %4,74 olasılıkla pozitif veya başka bir deyişle yaklaşık %95 olasılıkla negatif etikete sahiptir. Girdi örneğimiz üzerinde bazı değişiklikler yaptığımız durum Tablo 2’de gösterilmektedir.
Bazı değişikliklerle elde edilen sonuç 2 olmaktadır. Denklemde yerine koyduğumuzda elde edilen sonuç 0.88, yani %88 olasılıkla pozitif, %12 olasılıkla negatif çıkmaktadır. Bu şekilde saldırgan, gerçek durumda yaklaşık %5 olan olasılığı %88 oranına artırmayı başarmıştır.
Saldırgan Makine Öğrenmesi Yöntemleri
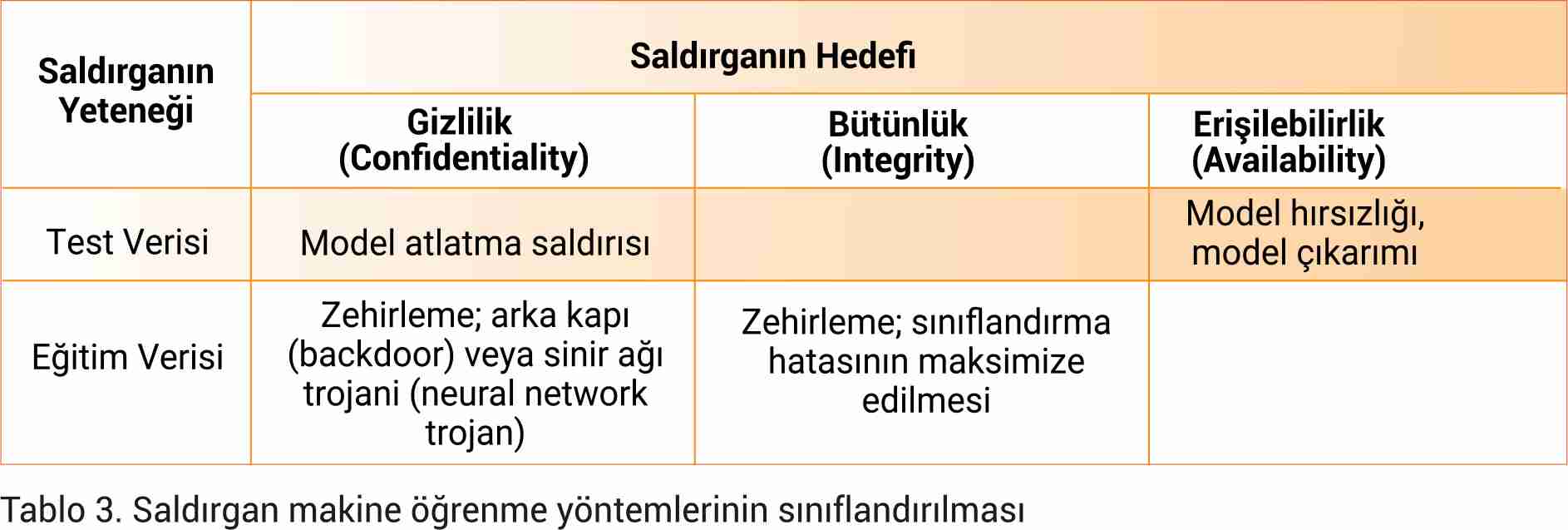
Siber güvenlikte yer alan CIA gizlilik, bütünlük, erişilebilirlik (Confidentiality, Integrity, Avaliability) bakış acısıyla saldırgan makine öğrenmesi Tablo 3’te gösterilmiştir.
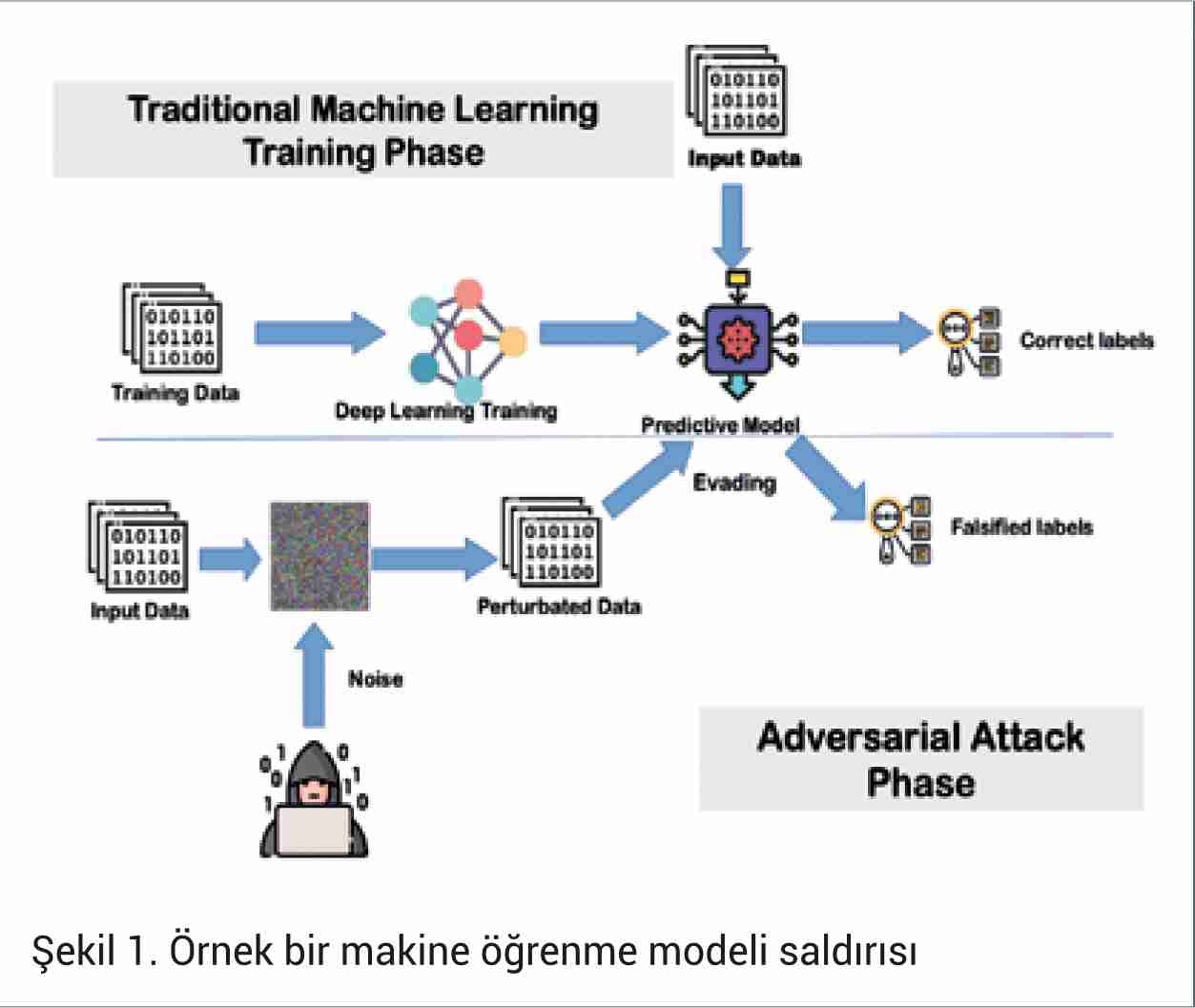
Saldırgan girdi örnekleri, bir makine öğrenme modelinin doğru şekilde sınıflandırdığı temiz bir görüntünün, makine öğrenme modeli tarafından yanlış sınıflandırılmasına neden olacak küçük bir bozulma eklenerek olusturulan yeni görüntülerdir. Bu saldırılar hedefli ve hedefsiz olmak üzere ikiye ayrılmaktadır. Hedefsiz bir saldırı ile modelin sınıflandırma performansını düşürmek amaçlanırken, bir hedefli saldırıyla modelin sadece belirli sınıfa ait sonuç üretmesi istenmektedir. Bu saldırıya örnek olarak, otonom bir araç üzerinde trafik işaretlerini algılayan ve buna göre davranacak modeli verebiliriz. Eğer modele yapılacak olan saldırı ile DUR (STOP) işaretini YOL VER (YIELD) olarak sınıflandırması sağlanır ise ölümcül bir kazaya neden olunabilir. Örnek bir saldırı akışı Şekil 1’de gösterilmiştir.
Saldırı Araçları Bu tip örneklerin oluşturulması ve modellere saldırı gerçekleştirilebilmesi amacıyla açık kaynak kodlu çeşitli kütüphaneler bulunmaktadır. Makine öğrenme modellerine saldırılar, bu araçlar kullanılarak oldukça kolay bir şekilde gerçekleştirilebilmektedir. Cleverhans1 ve IBM Adversarial Robustness Toobox2 bu alanda en çok kullanılan araçlardır. Bu araçların her ikisi de Tensorflow, Keras, PyTorch, Scikit-Learn gibi makine öğrenmesi alanında çok kullanılan algoritma kütüphanelerinin tamamına saldırı gerçekleştirebilmektedir. Github adreslerinde yer alan yeterli örnekleriyle saldırıların nasıl gerçekleştirilebileceği anlatılmaktadır. Saldırgan makine öğrenmesi (adversarial machine learning) alanında en çok kullanılan ve bu araçlarda da gerçekleştirimleri bulunan saldırı algoritmaları şunlardır:
- Fast-Gradient Sign Method Attack
- Targeted-Fast Gradient
- Sign Method Attack
- Basic Iterative MethodAttack
- DeepFool Attack
- Jacobian-based Saliency Map Attack
- Korunma Yöntemleri
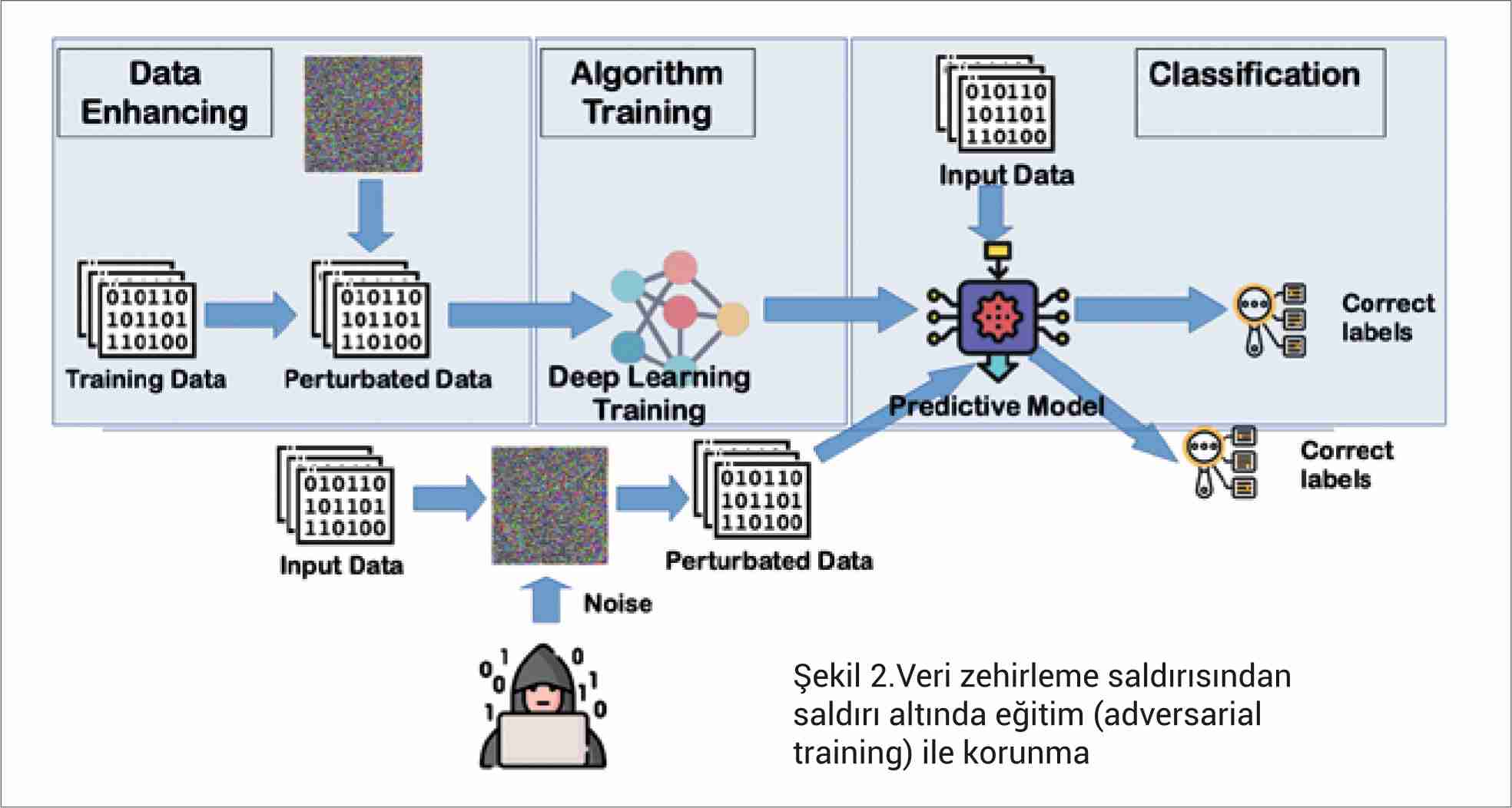
Model eğitilirken veya sınıflandırma aşamasında yaşanacak olan bu tip saldırılar için yapılabilecek ilk çözüm, saldırı altında eğitimdir (adversarial training). Özellikle görüntü sınıflandırma alanında oldukça sık kullanılan veri zenginleştirme (data augmentation) yöntemine benzer bir yaklaşımdır. Bu yaklaşımla bilinen bütün saldırı yöntemleri ile saldırgan örnekler oluşturularak, eğitim aşamasında kullanılacak olan veri kümesine bu saldırgan örnekler doğru etiketleri ile beraber eklenerek modelin oluşturulması hedeflenmektedir. Bu şekilde ileride modele yapılacak olan saldırılara karşı daha dayanıklı hale gelecektir. Şekil 2’de bu tip saldırıdan korunmak için gerekli olan adımlar gösterilmektedir.
İkinci olarak kullanılacak savunma yöntemi rassal girdi dönüşümüdür (random input transformation). Bu savunma yöntemi kullanılarak, girdi resimlerinin boyutlarının rassal olarak küçültülmesi, sıfır doldurma (zero padding) ile genişletmek gibi yöntemler uygulanmaktadır.
Kullanılabilecek başka bir yöntem ise kriptografik yöntemlerdir. Bu yöntemler, özellikle birden fazla veri kaynağının olduğu öğrenme aşamasında sistemin manipülasyonunun önüne geçilmesi açısından önem taşımaktadır. Homomorfik şifreleme, şifreli veriler üzerindeki aritmetik işlemlerin yapılabilmesine olanak sağlamaktadır. Bu şekilde, veri sahiplerinin verilerini şifrelemesini ve şifrelenmiş girdileri bir model sahibine ve muhtemelen diğer veri sahiplerine göndermesini sağlamaktadır. Model daha sonra şifrelenmiş girdi örneklerine uygulanmakta ve etiketleme sonucu, şifresini çözebilen ve istenen bilgileri elde edebilen uygun taraflara iletilmektedir. Microsoft SEAL veya HeLib gibi açık kaynak araçlar ve kütüphaneler kullanarak bu tip homomorfik şifreleme ürünleri geliştirilmesi oldukça kolaylaşmaktadır.
Sonuç
Yapay zekânın günlük hayatımızda kullanımı, önümüzdeki yıllarda da artarak devam edecek edecektir. Makine öğrenme modellerine dayalı geliştirilen uygulamaların çok fazla güvenlik zafiyetine sahip olduğu, saldırganlar tarafından bilinmektedir. Saldırgan makine öğrenmesi koruma konusunda bazı ilerlemeler sağlanmış olsa bile halen istenilen seviyelere ulaşılamamıştır. Özellikle savunma sanayi alanında faaliyet gösteren kuruluşlar tarafından geliştirilen ürünlerin içerisinde yer alacak bu tip algoritmaların ve eğitim verilerinin bu şekilde orijinal halleriyle kullanılması ileride büyük zararlar ortaya çıkarabilecektir. Güvenli yazılım geliştirme faaliyetlerinin tanımlanması gibi, güvenli model oluşturma adımlarının da tanımlanarak ürün geliştirmelerin yapılması bir zorunluluktur.
Kaynak: TÜBİTAK BİLGEM Teknoloji Dergisi